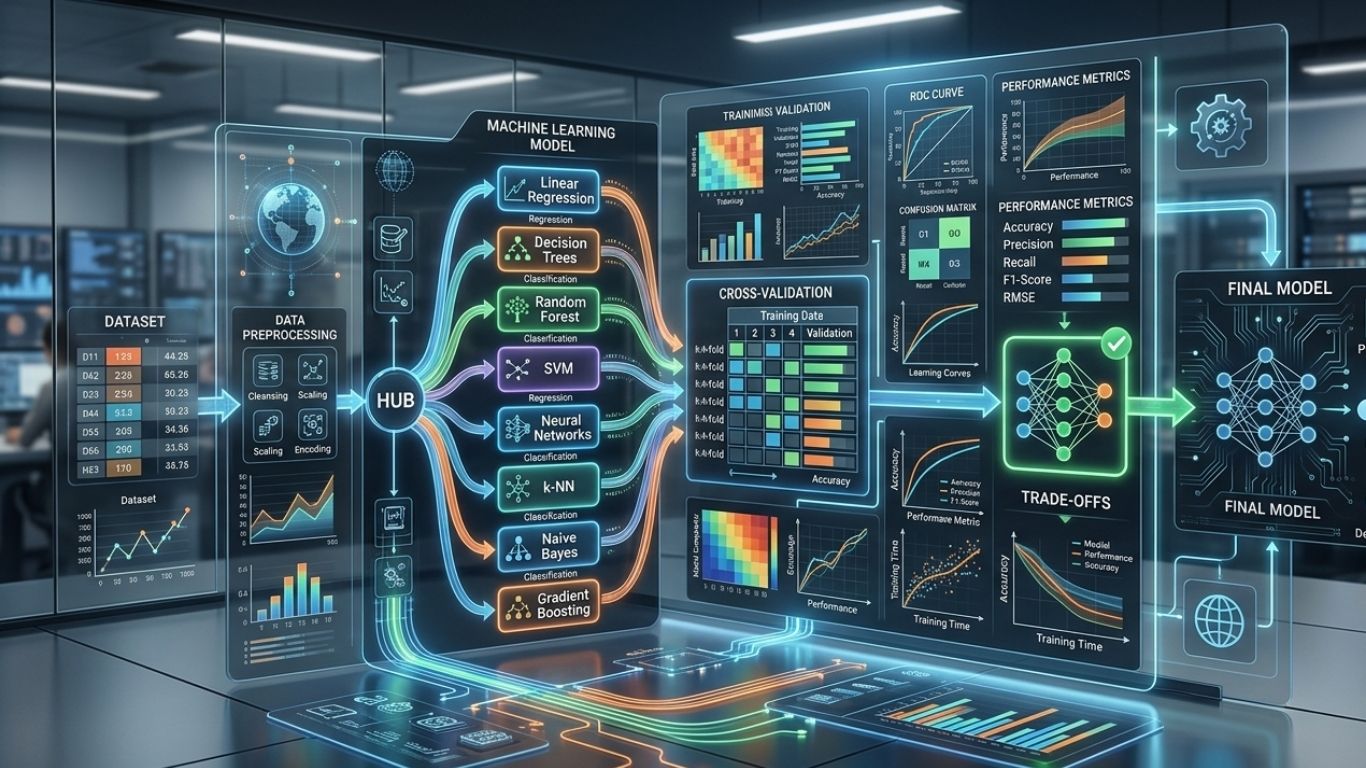
Model selection in machine learning is the process of choosing the best algorithm or model setup for a specific problem. In simple terms, it means deciding which model gives the best balance of accuracy, speed, simplicity, and reliability for your data and use case.
This matters because there is no single best model for every problem. A model that works well for image classification may not work well for fraud detection, forecasting, or customer churn prediction.
Why model selection is important
The right model can improve accuracy, reduce training time, and make deployment easier. The wrong model can waste resources, overfit the data, or fail to handle the problem correctly. Model selection in machine learning is not only about the highest score. It is also about choosing a model that fits business needs and data conditions.
For example, a highly accurate model may still be a poor choice if it is too slow, too complex, or too hard to explain.
Factors that influence model selection
| Factor | Why it matters | Example |
|---|---|---|
| Problem type | Different tasks need different models | Classification vs regression |
| Dataset size | Some models need more data | Deep learning often needs large datasets |
| Interpretability | Some businesses need explainable outputs | Banking, healthcare |
| Training speed | Faster models help in rapid testing | Logistic regression |
| Performance goal | Accuracy, recall, precision may differ | Fraud vs sales prediction |
Steps in selecting a model
The process usually starts by understanding the problem. Is it classification, regression, clustering, or anomaly detection? Then the data is prepared, features are selected, and multiple candidate models are tested.
The key is comparison under the same evaluation setup. Teams usually use validation sets or cross-validation to compare models fairly. Performance metrics should match the business goal. For fraud detection, recall may matter more than plain accuracy. For recommendation systems, ranking quality may matter more.
Common mistakes in model selection
One common mistake is choosing the most complex model too early. More advanced models are not always better. Sometimes a simpler algorithm performs just as well and is easier to maintain.
Another mistake is relying on one metric only. A model with high accuracy may still perform poorly on the minority class. Data leakage is another problem. If test information leaks into training, the selected model may look stronger than it really is.
Practical view of model selection
In real projects, model selection is usually iterative. Teams test a baseline model first, then compare stronger alternatives. The final choice depends not only on score, but also on stability, cost, explainability, and deployment needs.
That is why model selection in machine learning should be treated as both a technical and practical decision. The best model is the one that performs well and can actually be used effectively.
Final thoughts
Model selection in machine learning is about finding the right model for the right problem. It requires fair testing, proper metrics, and a clear understanding of business goals. The smartest choice is not always the most advanced model. It is the one that delivers dependable results in the real world.



Leave a Reply