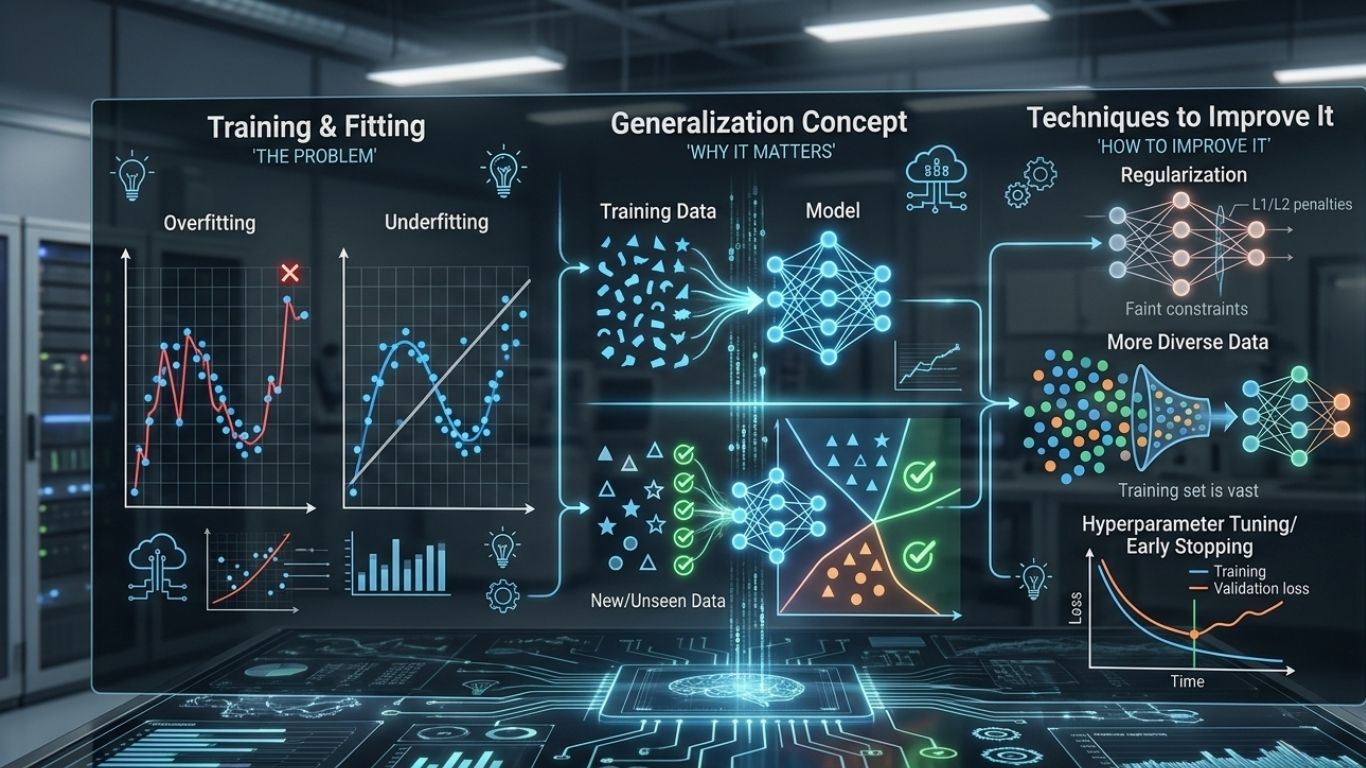
Generalization in machine learning means a model can perform well on new, unseen data, not just on the training dataset. In simple words, a model generalizes well when it learns the real pattern instead of memorizing old examples.
This is one of the most important goals in machine learning. A model that scores high during training but fails on fresh data is not useful in practice. That is why generalization in machine learning is often a better measure of quality than training accuracy alone.
Why generalization matters
Real-world systems always face unseen data. A recommendation engine will see new users. A fraud model will see new transactions. A medical model will see new patient records. If the model cannot generalize, it cannot make reliable predictions outside the training set.
Strong generalization is what makes machine learning practical. It shows that the model has captured a meaningful structure in the data.
What affects generalization
| Factor | Effect on generalization | Example |
|---|---|---|
| Data quality | Better data improves learning | Clear labels, fewer errors |
| Model complexity | Too much complexity can overfit | Deep model on tiny dataset |
| Feature relevance | Useful features improve signal | Income, not random ID |
| Regularization | Reduces overfitting | L1, L2, dropout |
| Validation strategy | Helps measure true performance | Train-validation-test split |
Generalization vs overfitting
The biggest enemy of generalization is overfitting. Overfitting happens when a model learns the training data too closely, including noise and random details. It then struggles on new data because it has not learned the real underlying pattern.
A model with good generalization finds a balance. It captures useful information from the training set, but it still remains flexible enough to work on unseen examples.
How to improve generalization
Better generalization starts with better data. A clean, diverse, and representative dataset gives the model a stronger foundation. After that, model tuning matters. Techniques such as regularization, cross-validation, early stopping, dropout, and feature selection can reduce overfitting and improve stability.
Simpler models can also generalize better when the dataset is limited. More complexity is not always better. The right level of complexity depends on the task and the amount of data available.
How to measure generalization
Generalization is usually measured by testing the model on data it did not see during training. Teams often compare training accuracy with validation and test accuracy. If training performance is much higher than test performance, the model may be overfitting.
Cross-validation is also useful because it checks performance across multiple data splits. This gives a more reliable picture of how well the model is likely to behave in the real world.
Final thoughts
Generalization in machine learning is the ability to perform well on new data. It is what separates a useful model from a memorized one. Good data, smart validation, appropriate model complexity, and overfitting control all help improve generalization. Without it, even high training accuracy has little real value.




Leave a Reply